3 RNN&Transformer
这一章的内容讲述了深度学习领域的第二次范式转移:从专注于处理网格数据的 CNN,转向处理序列数据的 RNN,最终收敛于目前统治 CV 和 NLP 领域的 Transformer。
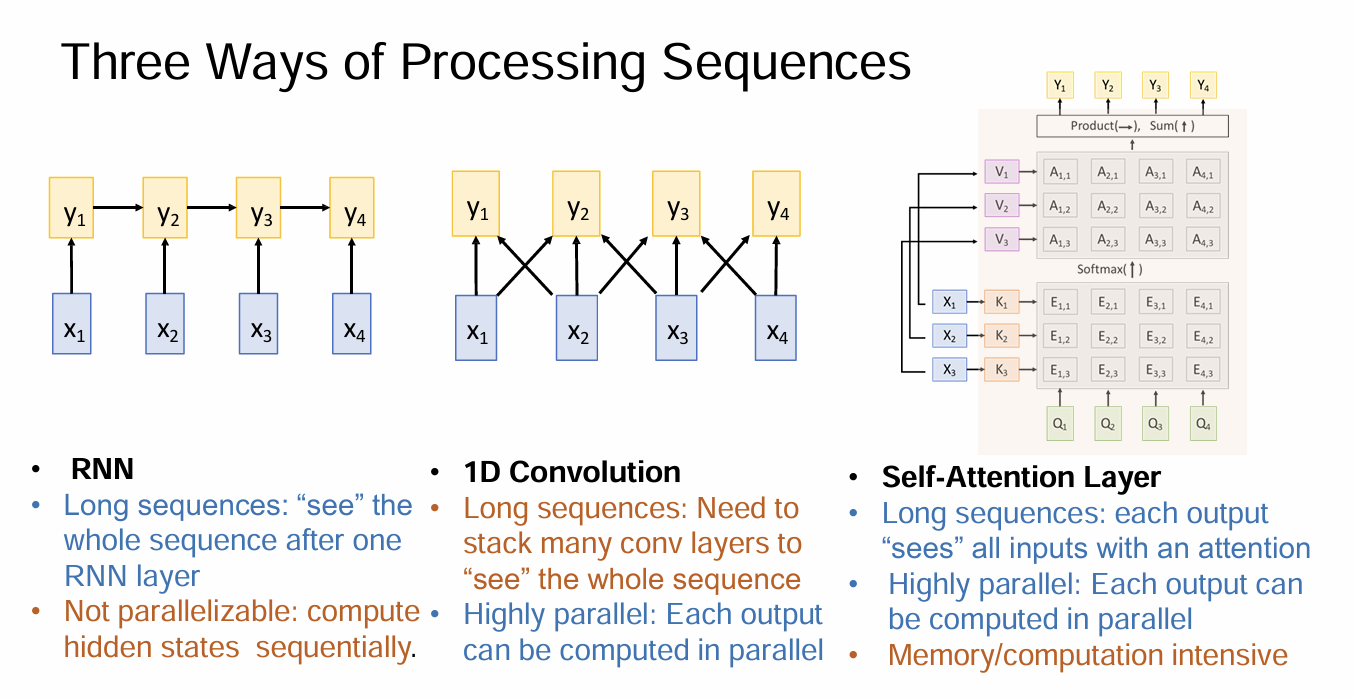
第一阶段:序列建模与 RNN (Recurrent Neural Networks)
在 CNN 中,我们处理的是固定大小的输入(如 $224 \times 224$ 的图像)。但在现实世界中,很多数据是变长的序列(如文本、语音、视频流)。
1. RNN 的核心思想
RNN 的设计初衷是为了处理序列数据。它的核心在于拥有一个“内部状态” (Internal State),即隐藏层 $h_t$。
- 递推公式:$ht = f_W(h{t-1}, x_t)$ 。
- $h_t$:当前时刻的隐藏状态。
- $h_{t-1}$:上一时刻的隐藏状态(记忆)。
- $x_t$:当前时刻的输入。
- $W$:权重参数。关键点:在所有时间步中,权重 $W$ 是共享的 。
- 这与 CNN 在空间上共享权重(卷积核)有异曲同工之妙,RNN 是在时间上共享权重。
2. 应用模式
RNN 极其灵活,PPT 展示了多种输入输出模式:
- One-to-Many:输入一张图,输出一串文字(Image Captioning 给图片打标题)。
- Many-to-One:输入一段视频(多帧),输出一个动作类别(Action Recognition)。
- Many-to-Many:机器翻译(Seq2Seq)或视频逐帧分类。
3. 致命缺陷:梯度消失/爆炸
虽然理论上 RNN 可以记住无限长的历史,但在反向传播(BPTT)时,梯度需要连乘。
- 如果权重矩阵的特征值小于 1,梯度会指数级衰减(梯度消失),导致模型“遗忘”长距离的信息。
- 如果特征值大于 1,梯度会指数级增长(梯度爆炸),导致训练不稳定。
- 解决方案:LSTM (Long Short-Term Memory)。PPT 提到了 LSTM 通过引入“门控机制”(遗忘门、输入门、输出门)来构建一条可以让梯度畅通无阻的“高速公路”(Cell State),从而有效缓解了梯度消失问题。
第二阶段:注意力机制 (Attention Mechanism)
RNN 最大的瓶颈在于:它试图把所有历史信息压缩到一个固定长度的向量 $h_t$ 中。当序列很长时,这几乎是不可能的。
Attention 的直觉:
在生成输出(比如写图片描述的下一个词)时,不要只盯着那个压缩后的 $h_t$,而是回头看一眼输入序列的所有位置,并根据相关性聚焦(Attend) 到最相关的部分。
- 软注意力 (Soft Attention):对所有输入区域加权求和,是可微的,可以端到端训练。
- 硬注意力 (Hard Attention):通过强化学习或采样选择某个区域,不可微。
第三阶段:Transformer 与 ViT (Vision Transformer)
这是目前 AI 领域最重要的架构变革。2017 年的论文《Attention Is All You Need》提出:如果我们有了注意力机制,还需要 RNN 的循环结构吗?答案是不需要。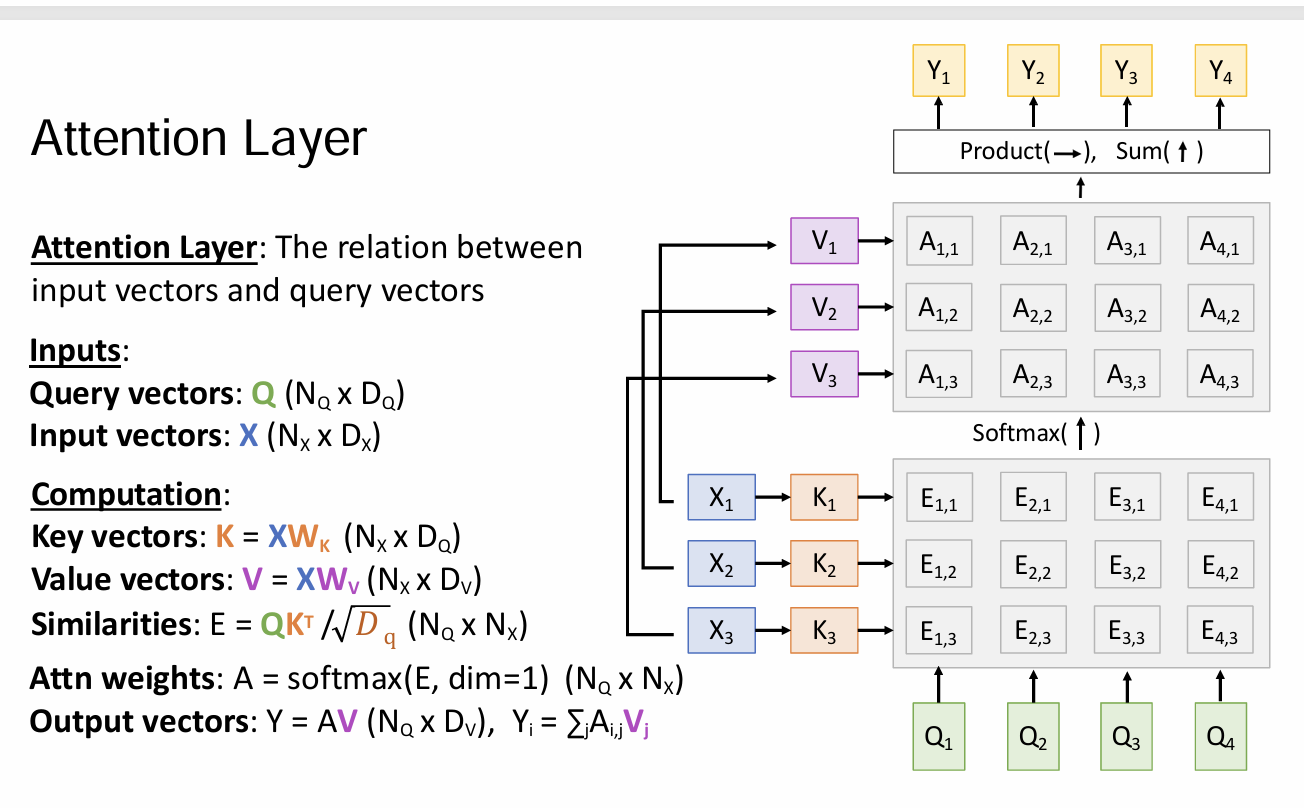
1. Transformer 的核心:自注意力 (Self-Attention)
Transformer 彻底抛弃了循环和卷积,完全依赖注意力机制。
- Q, K, V 模型:输入向量被映射为 Query (查询)、Key (键)、Value (值)。
- 计算公式:
- $QK^T$ 计算了查询和所有键的相似度(相关性)。
- Softmax 将其归一化为权重。
- 最后用这些权重对 $V$ 进行加权求和。
- 位置编码 (Positional Encoding):因为 Transformer 是并行处理所有 Token 的,它本身不知道“顺序”。所以必须手动加上位置信息。
2. Vision Transformer (ViT)
如何把为文本设计的 Transformer 用在图像上?PPT 详细介绍了 ViT 的做法:
- Patch Partition:把一张 $224 \times 224$ 的图切成 $16 \times 16$ 个小方块(Patch)。
- Linear Projection:把每个 Patch 拉平(Flatten)并通过一个全连接层映射为向量。这就相当于图片中的“单词”(Token)。
- Transformer Encoder:把这些 Patch 向量加上位置编码,直接扔进标准的 Transformer 编码器里。
- Class Token:借鉴 BERT,在序列开头加一个特殊的
[CLS]Token,最后用它的输出来做分类。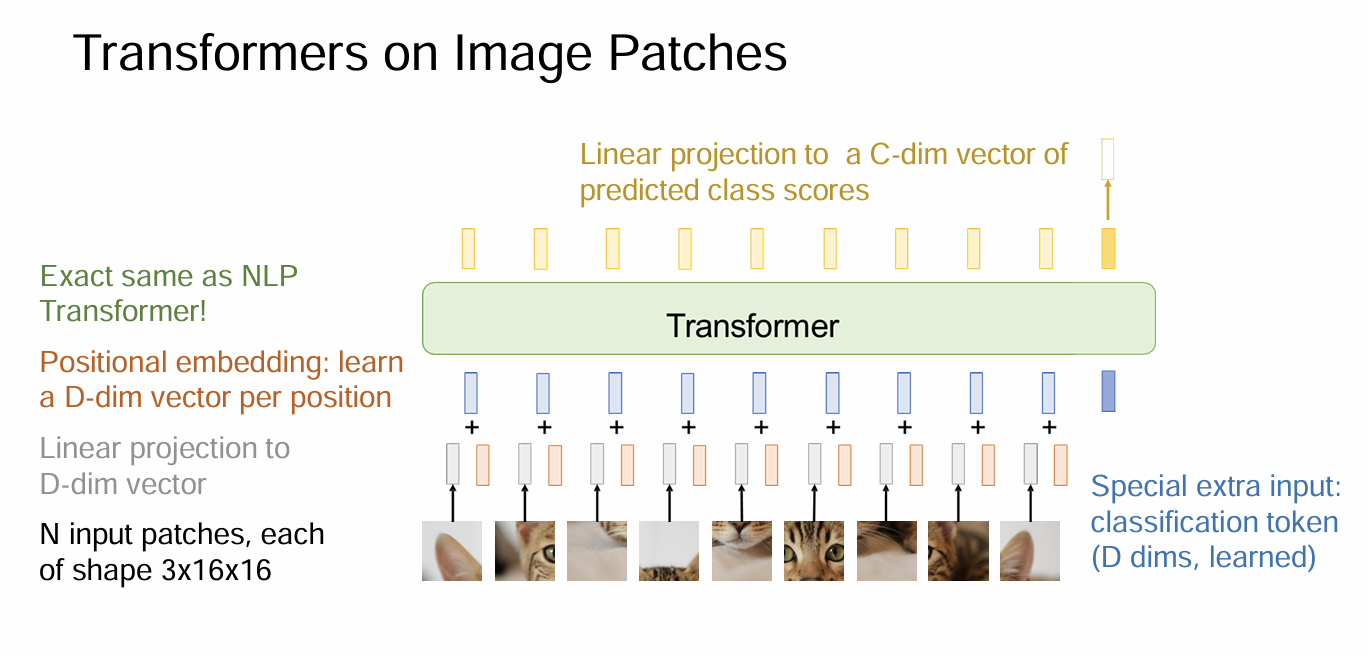
ViT vs CNN (Inductive Bias 的再思考):
- CNN 有很强的归纳偏置(局部性、平移等变性),所以它在小数据上学得快,泛化好。
- ViT 几乎没有这些偏置(它允许任意两个 Patch 之间直接交互,是全局的)。
- 缺点:在小数据集(如 ImageNet-1k)上容易过拟合,不如 ResNet。
- 优点:在大数据(如 JFT-300M)上预训练后,它的上限远高于 CNN,因为它不会被“局部窗口”限制住视野。
Swin Transformer
第四阶段:极简主义的 MLP-Mixer
[cite_start]在 ViT 之后,Google 提出了更激进的 MLP-Mixer [cite: 62]。
- 它连 Attention 都不用,只用全连接层(MLP)。
- 架构:
- Token-mixing MLP:在空间维度上(Patches 之间)混合信息。
- Channel-mixing MLP:在通道维度上(特征之间)混合信息。
- 这证明了只要能有效地混合空间和通道信息,具体的算子(卷积 vs 注意力 vs MLP)可能没那么重要,关键在于架构的整体设计。
总结
从 RNN 到 Transformer,我们见证了 “序列长度限制的突破” 和 “归纳偏置的移除”。
- RNN 让我们可以处理序列。
- Attention 让我们不再受限于定长记忆。
- Transformer/ViT 统一了 NLP 和 CV,证明了只要数据足够多,一个通用的、全局关联的模型可以学习到比人类设计的先验(卷积)更强大的特征表示。