5 Image Segmentation
1. 任务定义与分类
图像分割的核心是将图像中的每个像素分类到某个特定的标签。
- 语义分割 (Semantic Segmentation):将图像中的像素分类为“猫”、“草地”、“天空”等类别。不区分同一类别的不同实例(例如,两头牛被视为同一个“牛”类别的区域)。
- 实例分割 (Instance Segmentation):不仅要分类像素,还要区分同一类别的不同物体(例如,牛A和牛B是不同的实例)。
- 分类 vs. 分割:
- 图像分类:输入 $3 \times H \times W$,输出一个 1000 维的向量(类别概率)。
- 语义分割:输入 $3 \times H \times W$,输出 $C \times H \times W$ 的特征图(每个像素的类别概率)。
2. 早期方法与演进
2.1 滑动窗口 (Sliding Window)
最直观的方法是用一个小窗口遍历图像,提取每个窗口的特征并分类中心像素。
- 缺点:计算效率极低。相邻窗口有大量重叠区域,重复计算严重,且感受野受限,无法捕捉全局上下文。
2.2 全卷积化 (Fully Convolutional)
为了解决效率问题,我们将全连接层 (FC) 转换为卷积层。
- 操作:将分类网络末端的 $1 \times 1$ 向量输出,改为空间维度 $H’ \times W’$ 的特征图输出。
- 优势:可以接受任意尺寸的输入图像,并保留空间结构信息。
3. 核心架构:FCN 与 U-Net
这是深度学习时代语义分割的基石。
3.1 FCN (Fully Convolutional Networks)
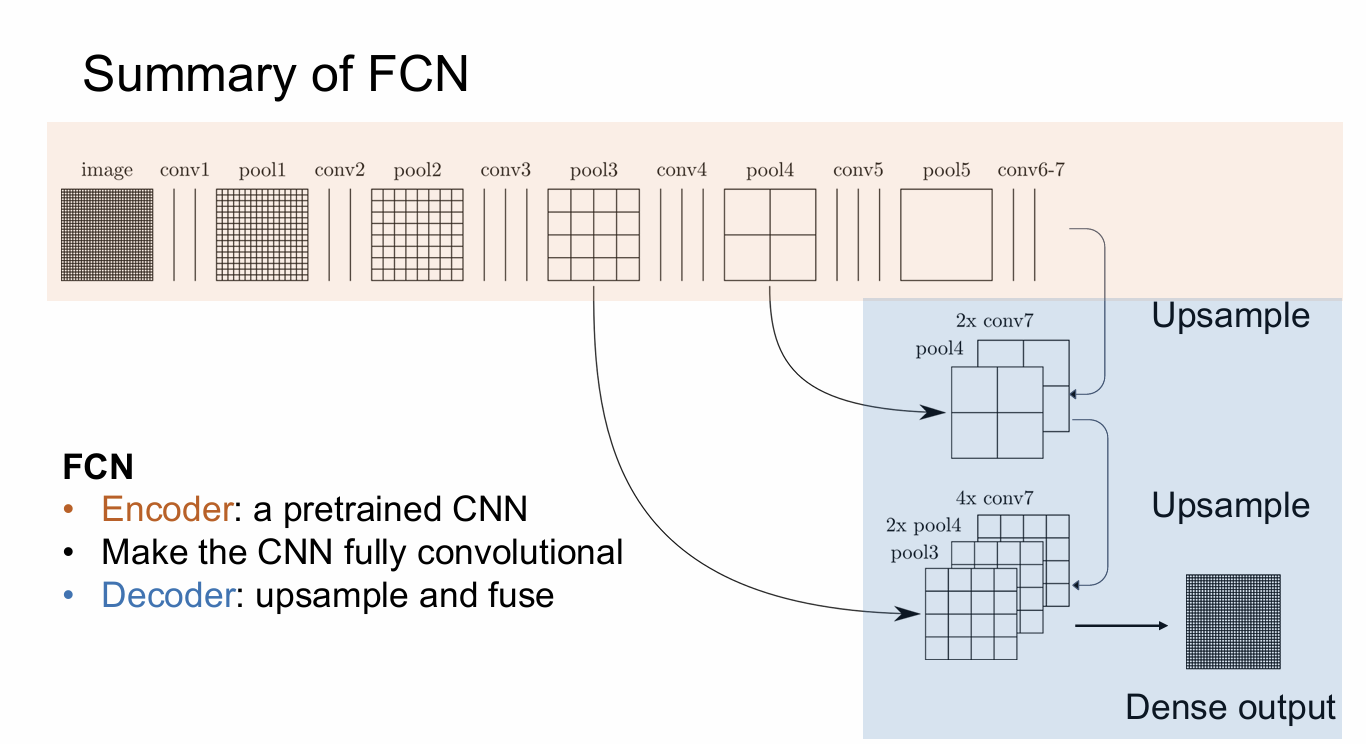
FCN 的核心思想是:预训练的编码器 + 上采样解码器 + 跳跃连接。
- 下采样 (Encoder):使用预训练的分类网络(如 VGG, ResNet),通过卷积和池化逐步减小特征图尺寸(例如从 $H \times W$ 降到 $H/32 \times W/32$),提取高层语义特征。
- 上采样 (Decoder):通过反卷积 (Deconvolution / Transposed Convolution) 或双线性插值,将低分辨率特征图恢复到原图尺寸。
- 跳跃连接 (Skip Connections):直接上采样得到的分割图往往边缘粗糙。FCN 将浅层(高分辨率、低语义)的特征图与深层(低分辨率、高语义)的上采样结果相加,融合细节与语义,显著提升了边缘精度。
3.2 U-Net
U-Net 是 FCN 的一种变体,最初用于生物医学图像分割,具有对称的编码器-解码器 (Encoder-Decoder) 结构。
- 结构:形状呈 “U” 型。左侧是收缩路径(下采样),右侧是扩张路径(上采样)。
- 特征融合:与 FCN 的相加不同,U-Net 使用 Concat (拼接) 操作,将编码器同层级的高分辨率特征拼接到解码器对应的层级。
- 优势:极大地保留了位置信息,使得网络在通过少量样本训练后也能获得非常精细的分割结果。U-Net 及其变体目前仍是扩散模型(如 Stable Diffusion)和医学影像分析的主流架构。
4. 上采样技术 (Upsampling Methods)
为了将低分辨率特征图恢复到原图尺寸,需要使用上采样操作。
4.1 插值法 (Interpolation)
- 最近邻插值 (Nearest Neighbor):简单复制像素,产生锯齿状边缘。
- 双线性插值 (Bilinear):基于距离加权平均,结果更平滑,不需要学习参数。
4.2 反池化 (Unpooling)
- Max Unpooling:在 Max Pooling 阶段记录最大值的位置索引 (Indices)。在反池化阶段,将数值填回原来的位置,其余位置补零。这种方法保留了强特征的空间结构。
4.3 转置卷积 (Transposed Convolution / Deconvolution)
这是一种可学习的上采样方法。
- 原理:可以理解为卷积的逆运算(在数学形式上),或者是对输入像素周围填充零后再进行卷积。它允许网络学习最佳的上采样方式,而不仅仅是固定的插值。
- 棋盘效应 (Checkerboard Artifacts):如果不当设置步长和核大小,转置卷积容易产生棋盘状的伪影。
5. 前沿进展:Transformers 与 SAM
5.1 Vision Transformers (ViT) for Segmentation
随着 Transformer 在视觉领域的崛起(如 ViT),研究者开始用 Transformer 替代 CNN 作为骨干网络。
- SETR (Segmentation Transformer):直接将图像切块 (Patch) 输入 Transformer 编码器,利用自注意力机制捕捉全局上下文,然后通过简单的解码器恢复分辨率。
- 优势:相比 CNN 局部的感受野,Transformer 天生具有全局感受野,能更好地处理长距离依赖。
5.2 Segment Anything Model (SAM)
这是 Meta 提出的通用分割大模型。
- 特点:
- 提示工程 (Promptable):支持点、框、文本等多种交互式提示。
- 零样本泛化 (Zero-shot):在海量数据(SA-1B 数据集)上预训练后,无需微调即可分割从未见过的物体。
- 架构:基于强大的 Image Encoder (ViT) 和轻量级的 Prompt Encoder + Mask Decoder。
6. 总结 (Summary)
- 核心范式:Pixel-in, Pixel-out(像素进,像素出)。
- 关键架构:
- FCN:开创了全卷积分割的先河,引入跳跃连接。
- U-Net:对称结构 + Concat 跳跃连接,不仅恢复语义,还完美保留了细节。
- 上采样:不仅有固定的插值,还有可学习的转置卷积。
- 最新趋势:Transformer 架构(全局建模)和基础模型(如 SAM)正在重新定义分割任务的边界。